Senior Site Reliability Engineer Interview Scorecard
 ZYTHR Resources •
September 11, 2025
ZYTHR Resources •
September 11, 2025
TL;DR
A focused interview scorecard for hiring a Senior Site Reliability Engineer to evaluate technical craft, operational rigor, and team impact. It balances measurable reliability outcomes with collaboration and mentorship expectations to guide objective hiring decisions.
Who this scorecard is for
Designed for hiring managers, tech leads, and interviewers assessing senior SRE candidates. Useful to recruiters for screening and to interview panels for consistent scoring and feedback.
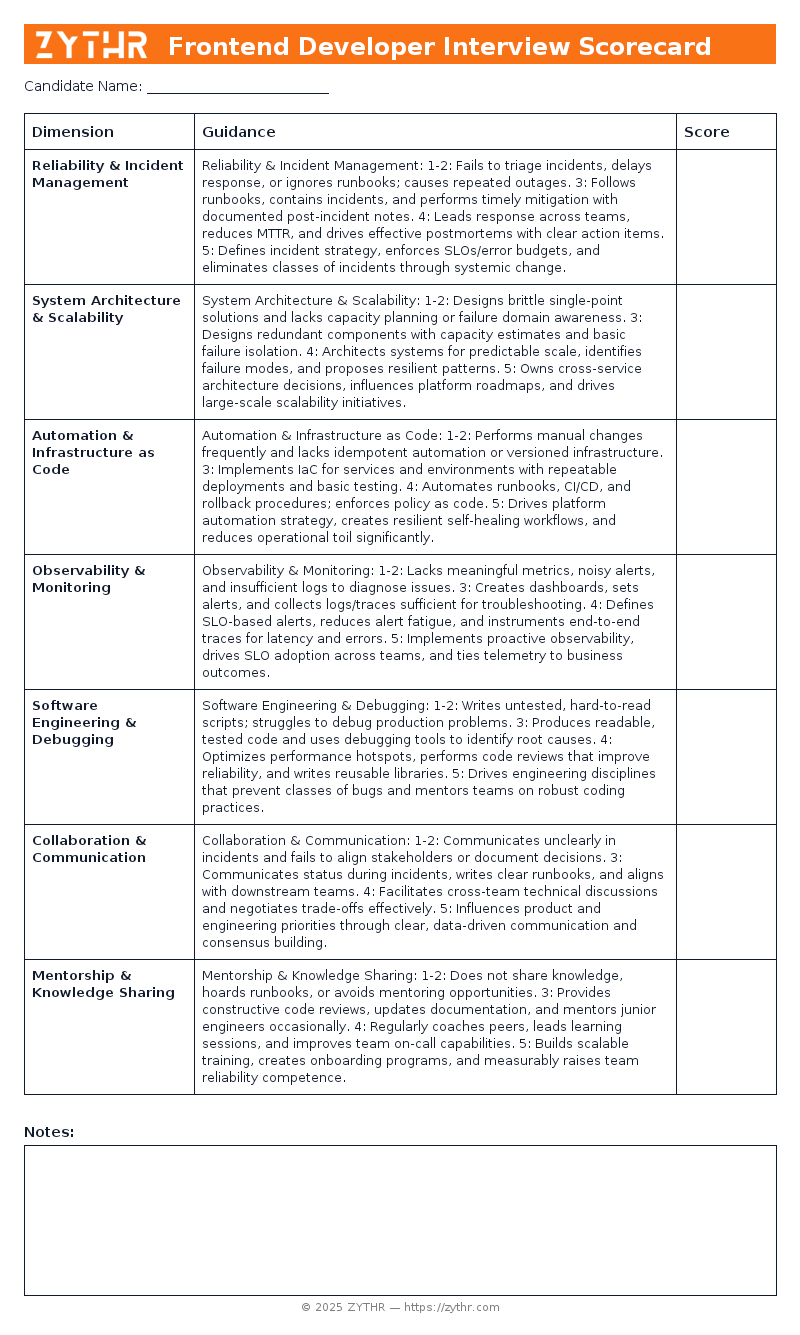
Preview the Scorecard
See what the Senior Site Reliability Engineer Interview Scorecard looks like before you download it.
How to use and calibrate
- Pick the level (Junior, Mid, Senior, or Staff) and adjust anchor examples accordingly.
- Use the quick checklist during the call; fill the rubric within 30 minutes after.
- Or use ZYTHR to transcribe the interview and automatically fill in the scorecard live.
- Run monthly calibration with sample candidate answers to align expectations.
- Average across interviewers; avoid single-signal decisions.
Detailed rubric with anchor behaviors
Reliability & Incident Management
- 1–2: Fails to triage incidents, delays response, or ignores runbooks; causes repeated outages.
- 3: Follows runbooks, contains incidents, and performs timely mitigation with documented post-incident notes.
- 4: Leads response across teams, reduces MTTR, and drives effective postmortems with clear action items.
- 5: Defines incident strategy, enforces SLOs/error budgets, and eliminates classes of incidents through systemic change.
System Architecture & Scalability
- 1–2: Designs brittle single-point solutions and lacks capacity planning or failure domain awareness.
- 3: Designs redundant components with capacity estimates and basic failure isolation.
- 4: Architects systems for predictable scale, identifies failure modes, and proposes resilient patterns.
- 5: Owns cross-service architecture decisions, influences platform roadmaps, and drives large-scale scalability initiatives.
Automation & Infrastructure as Code
- 1–2: Performs manual changes frequently and lacks idempotent automation or versioned infrastructure.
- 3: Implements IaC for services and environments with repeatable deployments and basic testing.
- 4: Automates runbooks, CI/CD, and rollback procedures; enforces policy as code.
- 5: Drives platform automation strategy, creates resilient self-healing workflows, and reduces operational toil significantly.
Observability & Monitoring
- 1–2: Lacks meaningful metrics, noisy alerts, and insufficient logs to diagnose issues.
- 3: Creates dashboards, sets alerts, and collects logs/traces sufficient for troubleshooting.
- 4: Defines SLO-based alerts, reduces alert fatigue, and instruments end-to-end traces for latency and errors.
- 5: Implements proactive observability, drives SLO adoption across teams, and ties telemetry to business outcomes.
Software Engineering & Debugging
- 1–2: Writes untested, hard-to-read scripts; struggles to debug production problems.
- 3: Produces readable, tested code and uses debugging tools to identify root causes.
- 4: Optimizes performance hotspots, performs code reviews that improve reliability, and writes reusable libraries.
- 5: Drives engineering disciplines that prevent classes of bugs and mentors teams on robust coding practices.
Collaboration & Communication
- 1–2: Communicates unclearly in incidents and fails to align stakeholders or document decisions.
- 3: Communicates status during incidents, writes clear runbooks, and aligns with downstream teams.
- 4: Facilitates cross-team technical discussions and negotiates trade-offs effectively.
- 5: Influences product and engineering priorities through clear, data-driven communication and consensus building.
Mentorship & Knowledge Sharing
- 1–2: Does not share knowledge, hoards runbooks, or avoids mentoring opportunities.
- 3: Provides constructive code reviews, updates documentation, and mentors junior engineers occasionally.
- 4: Regularly coaches peers, leads learning sessions, and improves team on-call capabilities.
- 5: Builds scalable training, creates onboarding programs, and measurably raises team reliability competence.
Scoring and weighting
Default weights (adjust per role):
| Dimension | Weight |
|---|---|
| Reliability & Incident Management | 20% |
| System Architecture & Scalability | 18% |
| Automation & Infrastructure as Code | 16% |
| Observability & Monitoring | 14% |
| Software Engineering & Debugging | 12% |
| Collaboration & Communication | 10% |
| Mentorship & Knowledge Sharing | 10% |
Final score = weighted average across dimensions. Require at least two “4+” signals for Senior+ roles.
Complete Examples
Senior Site Reliability Engineer Scorecard — Great Candidate
| Dimension | Notes | Score (1–5) |
|---|---|---|
| Reliability & Incident Management | Led complex incident to root cause and implemented preventive system changes | 5 |
| System Architecture & Scalability | Proposed architecture that enabled 10x traffic growth with minimal changes | 5 |
| Automation & Infrastructure as Code | Built automated self-healing workflows that removed routine manual ops | 5 |
| Observability & Monitoring | Implemented SLOs and tracing that shortened diagnosis time across services | 5 |
| Software Engineering & Debugging | Authored libraries or fixes that prevented frequent production regressions | 5 |
| Collaboration & Communication | Led cross-org initiative that improved reliability through stakeholder alignment | 5 |
| Mentorship & Knowledge Sharing | Created training/onboarding that shortened ramp time for new SREs | 5 |
Senior Site Reliability Engineer Scorecard — Good Candidate
| Dimension | Notes | Score (1–5) |
|---|---|---|
| Reliability & Incident Management | Contains incidents and produces clear postmortems with fixes | 3 |
| System Architecture & Scalability | Designs redundant, horizontally scalable components | 3 |
| Automation & Infrastructure as Code | Delivers reproducible IaC and CI/CD pipelines | 3 |
| Observability & Monitoring | Provides clear dashboards and actionable alerts | 3 |
| Software Engineering & Debugging | Writes tested automation and debugs issues using profiling/tracing | 3 |
| Collaboration & Communication | Writes clear runbooks and coordinates fixes across teams | 3 |
| Mentorship & Knowledge Sharing | Regularly reviews code and updates runbooks | 3 |
Senior Site Reliability Engineer Scorecard — No-Fit Candidate
| Dimension | Notes | Score (1–5) |
|---|---|---|
| Reliability & Incident Management | Unable to triage outages or execute basic runbook steps | 1 |
| System Architecture & Scalability | Suggests single-node designs or ignores capacity constraints | 1 |
| Automation & Infrastructure as Code | Relies on ad-hoc shell edits and manual server changes | 1 |
| Observability & Monitoring | Produces high-noise alerts and sparse telemetry | 1 |
| Software Engineering & Debugging | Produces brittle scripts and cannot reproduce production bugs | 1 |
| Collaboration & Communication | Fails to update stakeholders during incidents | 1 |
| Mentorship & Knowledge Sharing | No evidence of mentoring or documentation contributions | 1 |
Recruiter FAQs about this scorecard
Q: Do scorecards actually reduce bias?
A: Yes—when you use the same questions, anchored rubrics, and require evidence-based notes.
Q: How many dimensions should we score?
A: Stick to 6–8 core dimensions. More than 10 dilutes signal.
Q: How do we calibrate interviewers?
A: Run monthly sessions with sample candidate answers and compare scores.
Q: How do we handle candidates who spike in one area but are weak elsewhere?
A: Use weighted average but define non-negotiables.
Q: How should we adapt this for Junior vs. Senior roles?
A: Keep dimensions the same but raise expectations for Senior+.
Q: Does this work for take-home or live coding?
A: Yes. Apply the same dimensions, but adjust scoring criteria for context.
Q: Where should results live?
A: Store structured scores and notes in your ATS or ZYTHR.
Q: What if interviewers disagree widely?
A: Require written evidence, reconcile in debrief, or add a follow-up interview.
Q: Can this template be reused for other roles?
A: Yes. Swap technical dimensions for role-specific ones, keep collaboration and communication.
Q: Can ZYTHR auto-populate the scorecard?
A: Yes. ZYTHR can transcribe interviews, tag signals, and live-populate the scorecard.
See Live Scorecards in Action
ZYTHR is not only a resume-screening took, it also automatically transcribes interviews and live-populates scorecards, giving your team a consistent view of every candidate in real time.