Junior Site Reliability Engineer Interview Scorecard
 ZYTHR Resources •
September 11, 2025
ZYTHR Resources •
September 11, 2025
TL;DR
This scorecard evaluates core SRE skills and collaboration behaviors for a Junior Site Reliability Engineer role. It provides clear, observable criteria to standardize interview assessments and hiring decisions.
Who this scorecard is for
For hiring managers, tech leads, and recruiters evaluating early-career SRE candidates. Useful in technical interviews, incident simulations, and take-home exercises to compare candidates against consistent expectations.
Preview the Scorecard
See what the Junior Site Reliability Engineer Interview Scorecard looks like before you download it.
How to use and calibrate
- Pick the level (Junior, Mid, Senior, or Staff) and adjust anchor examples accordingly.
- Use the quick checklist during the call; fill the rubric within 30 minutes after.
- Or use ZYTHR to transcribe the interview and automatically fill in the scorecard live.
- Run monthly calibration with sample candidate answers to align expectations.
- Average across interviewers; avoid single-signal decisions.
Detailed rubric with anchor behaviors
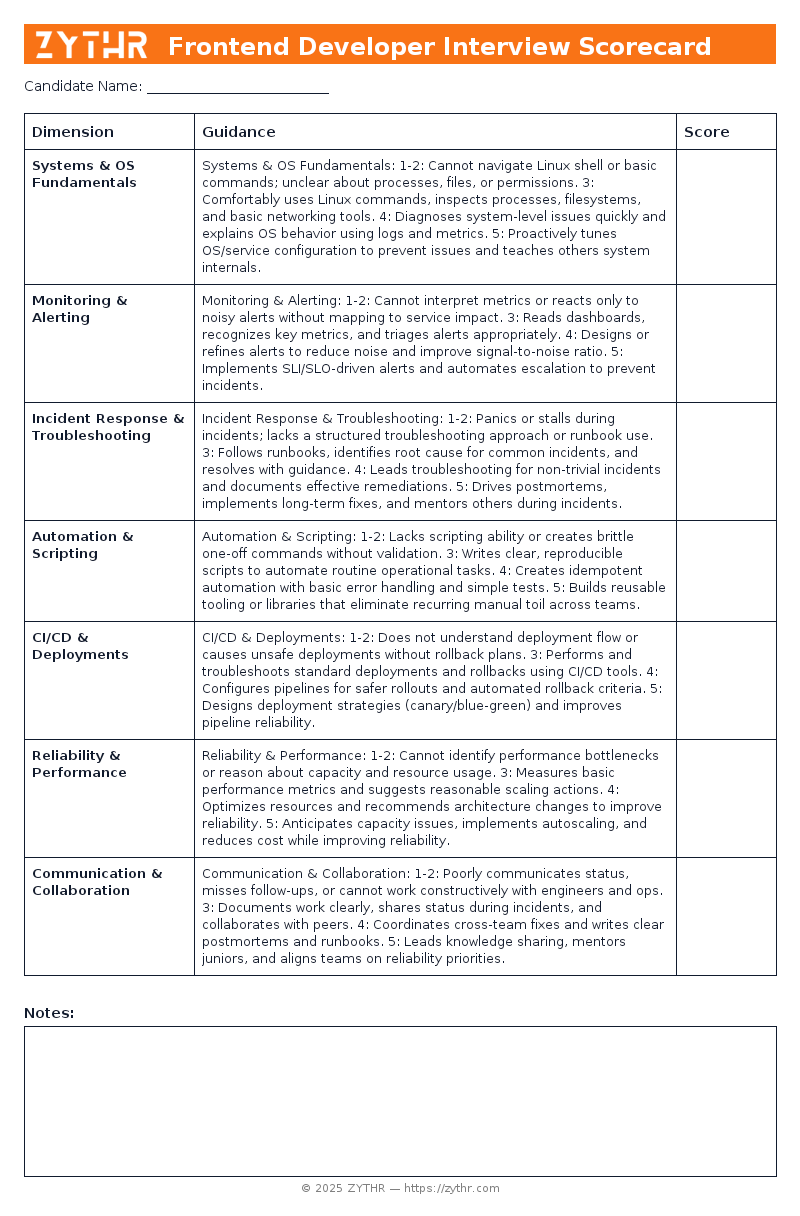
Systems & OS Fundamentals
- 1–2: Cannot navigate Linux shell or basic commands; unclear about processes, files, or permissions.
- 3: Comfortably uses Linux commands, inspects processes, filesystems, and basic networking tools.
- 4: Diagnoses system-level issues quickly and explains OS behavior using logs and metrics.
- 5: Proactively tunes OS/service configuration to prevent issues and teaches others system internals.
Monitoring & Alerting
- 1–2: Cannot interpret metrics or reacts only to noisy alerts without mapping to service impact.
- 3: Reads dashboards, recognizes key metrics, and triages alerts appropriately.
- 4: Designs or refines alerts to reduce noise and improve signal-to-noise ratio.
- 5: Implements SLI/SLO-driven alerts and automates escalation to prevent incidents.
Incident Response & Troubleshooting
- 1–2: Panics or stalls during incidents; lacks a structured troubleshooting approach or runbook use.
- 3: Follows runbooks, identifies root cause for common incidents, and resolves with guidance.
- 4: Leads troubleshooting for non-trivial incidents and documents effective remediations.
- 5: Drives postmortems, implements long-term fixes, and mentors others during incidents.
Automation & Scripting
- 1–2: Lacks scripting ability or creates brittle one-off commands without validation.
- 3: Writes clear, reproducible scripts to automate routine operational tasks.
- 4: Creates idempotent automation with basic error handling and simple tests.
- 5: Builds reusable tooling or libraries that eliminate recurring manual toil across teams.
CI/CD & Deployments
- 1–2: Does not understand deployment flow or causes unsafe deployments without rollback plans.
- 3: Performs and troubleshoots standard deployments and rollbacks using CI/CD tools.
- 4: Configures pipelines for safer rollouts and automated rollback criteria.
- 5: Designs deployment strategies (canary/blue-green) and improves pipeline reliability.
Reliability & Performance
- 1–2: Cannot identify performance bottlenecks or reason about capacity and resource usage.
- 3: Measures basic performance metrics and suggests reasonable scaling actions.
- 4: Optimizes resources and recommends architecture changes to improve reliability.
- 5: Anticipates capacity issues, implements autoscaling, and reduces cost while improving reliability.
Communication & Collaboration
- 1–2: Poorly communicates status, misses follow-ups, or cannot work constructively with engineers and ops.
- 3: Documents work clearly, shares status during incidents, and collaborates with peers.
- 4: Coordinates cross-team fixes and writes clear postmortems and runbooks.
- 5: Leads knowledge sharing, mentors juniors, and aligns teams on reliability priorities.
Scoring and weighting
Default weights (adjust per role):
| Dimension | Weight |
|---|---|
| Systems & OS Fundamentals | 18% |
| Monitoring & Alerting | 14% |
| Incident Response & Troubleshooting | 18% |
| Automation & Scripting | 16% |
| CI/CD & Deployments | 10% |
| Reliability & Performance | 14% |
| Communication & Collaboration | 10% |
Final score = weighted average across dimensions. Require at least two “4+” signals for Senior+ roles.
Complete Examples
Junior Site Reliability Engineer Scorecard — Great Candidate
| Dimension | Notes | Score (1–5) |
|---|---|---|
| Systems & OS Fundamentals | Tuned kernel or service settings to prevent a recurring production issue | 5 |
| Monitoring & Alerting | Created SLI-based alerts that reduced false positives | 5 |
| Incident Response & Troubleshooting | Led a postmortem and delivered a permanent fix | 5 |
| Automation & Scripting | Authored a shared automation tool that removed recurring manual steps | 5 |
| CI/CD & Deployments | Implemented canary deployments to reduce deployment risk | 5 |
| Reliability & Performance | Implemented autoscaling and reduced latency under peak load | 5 |
| Communication & Collaboration | Led a cross-team initiative to improve on-call handovers and reduce incidents | 5 |
Junior Site Reliability Engineer Scorecard — Good Candidate
| Dimension | Notes | Score (1–5) |
|---|---|---|
| Systems & OS Fundamentals | Uses system tools to identify a process or disk issue | 3 |
| Monitoring & Alerting | Configures dashboards and escalates meaningful alerts | 3 |
| Incident Response & Troubleshooting | Resolves a production outage using runbook steps | 3 |
| Automation & Scripting | Wrote a script to automate log rotation or backups | 3 |
| CI/CD & Deployments | Performs deployments and handles rollbacks | 3 |
| Reliability & Performance | Measured load and recommended scaling to prevent overload | 3 |
| Communication & Collaboration | Writes clear runbooks and keeps stakeholders informed | 3 |
Junior Site Reliability Engineer Scorecard — No-Fit Candidate
| Dimension | Notes | Score (1–5) |
|---|---|---|
| Systems & OS Fundamentals | Struggles with basic shell tasks and reading logs | 1 |
| Monitoring & Alerting | Cannot explain purpose of key service metrics | 1 |
| Incident Response & Troubleshooting | Unable to follow incident runbook or find root cause | 1 |
| Automation & Scripting | Relies on manual repetitive commands for routine tasks | 1 |
| CI/CD & Deployments | Breaks builds or cannot explain deployment steps | 1 |
| Reliability & Performance | Fails to identify why CPU or latency spiked | 1 |
| Communication & Collaboration | Fails to communicate during incidents or misses handoffs | 1 |
Recruiter FAQs about this scorecard
Q: Do scorecards actually reduce bias?
A: Yes—when you use the same questions, anchored rubrics, and require evidence-based notes.
Q: How many dimensions should we score?
A: Stick to 6–8 core dimensions. More than 10 dilutes signal.
Q: How do we calibrate interviewers?
A: Run monthly sessions with sample candidate answers and compare scores.
Q: How do we handle candidates who spike in one area but are weak elsewhere?
A: Use weighted average but define non-negotiables.
Q: How should we adapt this for Junior vs. Senior roles?
A: Keep dimensions the same but raise expectations for Senior+.
Q: Does this work for take-home or live coding?
A: Yes. Apply the same dimensions, but adjust scoring criteria for context.
Q: Where should results live?
A: Store structured scores and notes in your ATS or ZYTHR.
Q: What if interviewers disagree widely?
A: Require written evidence, reconcile in debrief, or add a follow-up interview.
Q: Can this template be reused for other roles?
A: Yes. Swap technical dimensions for role-specific ones, keep collaboration and communication.
Q: Can ZYTHR auto-populate the scorecard?
A: Yes. ZYTHR can transcribe interviews, tag signals, and live-populate the scorecard.
See Live Scorecards in Action
ZYTHR is not only a resume-screening took, it also automatically transcribes interviews and live-populates scorecards, giving your team a consistent view of every candidate in real time.